3年ほど前に、単眼カメラでの深度推定の結果は今ひとつだったが、最新の深度推定のアルゴリズムDepthAnything2を試してみたところ、かなり進化している。前回と同じ画像で試してみた。
Depth Anything
Depth Anythingは2024年4月に発表された単眼カメラ画像の深度推定モデル。最近画像系でもTransformerが使われるようになってきているが、Detph AnythingもTransformerを使用している。これまではステレオカメラなどからの画像をもとにデータを用意していたため学習コストが掛かっていたが、未ラベルの画像を大量に収集して自動的にアノテーションするエンジンを設計し、62M個の多様なデータセットでモデルの汎化性能を向上させている。
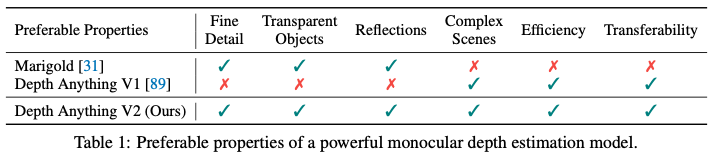
Depth Anything V2は2024年6月に発表された。以下の表はV2の論文から引用したものだが、Stable DiffusionをベースとしたMarigoldに比べて、V1で劣っていた精緻さ、透明な物体、光の反射などに対して改善を加えた形になっている。
使用方法
Githubに公開されてあるコードをGoogle Colabで実行しただけで、簡単に実行ができる。コードをColab上に落とし、パッケージをインストールしたら、以下のコマンドを実行するだけでDepth画像を出力してくれる。vitlはLargeモデルで、vitsはSmall、vitbはBaseモデルを指定できる。
#画像の場合
python run.py --encoder vitl --img-path <path> --outdir <outdir>
#動画の場合
python run_video.py --encoder vitl --video-path <path> --outdir <outdir>
結果
以下がLargeモデルで前回と同じ画像で実行した結果である。遠近感に特に矛盾のない結果になっている。



以下は動画での実行結果(出力動画のサイズが大きいので、このページの動画は解像度を落としている)。動いているものに対しても距離感がうまく出せている。中央の支柱の色がフレームごとに少し色が変わるのは、回転している遊具の影の影響からか、フレームごとに結果にはばらつきがあるのかもしれない。
モデルをSmallに変えた結果が以下。そう大きな大差は感じない。もっと複雑なパターンの画像で試すと差分が見えてくるのかもしれない。
3年前に試したモデルに比べると、格段に精度が上がっている。複雑な状況の画像でも遠近感をうまく出せるようになってきている。細かい距離精度がどこまで出せるかはあり、実用的にどこまではあるが、正確な距離を必要としないところではある程度使えるのではと思う。
CoreMLもサポートされているので、iPhoneでも動かすことができるので、今後これを活用したアプリが出てくる可能性はある。ただし、Smallであっても、推論時間は結構掛かったので、リアルタイム性が必要なアプリケーションは難しそうである。