文字認識技術のOCR(Optical Character Recognition)は印刷された文字や手書き文字を読み取る技術で、デジタル化には欠かせない技術だが、ディープラーニングが適用されて精度が上がってきているとのことで、PaddleOCRとEasyOCRを比較してみた。
OCRとは
OCR自体は以前からある技術で、紙に書かれた文字を読み取る技術で、最近は業務効率化やデジタル化の一環として、これまで紙ベースで保管していてた帳票や資料のデジタル化などで使われている。名刺管理アプリの文字認識、最近だとマネーフォワードでの領収書読み取りなど、色々なところで実用化されている。手軽に使える環境も整っていて、tesseractなどはフリーで使用できる。
OCRも最近のディープラーニングの発展とともに、AIを活用するようになってきており、AIOCRという形で性能が上がってきている。今回2つのAIOCRを試してみた。
EasyOCR
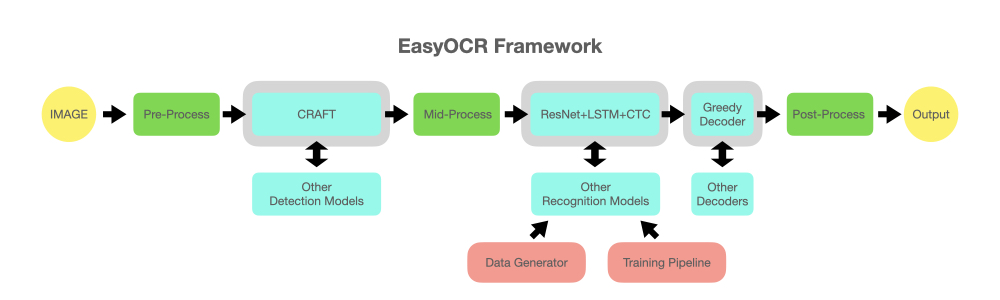
EasyOCRは80の言語をサポートしている。以下のような構造になっていて、画像認識と文字の前後関係をLSTMで繋ぐような構造になっている様子。Githubはこちら。
PaddleOCR
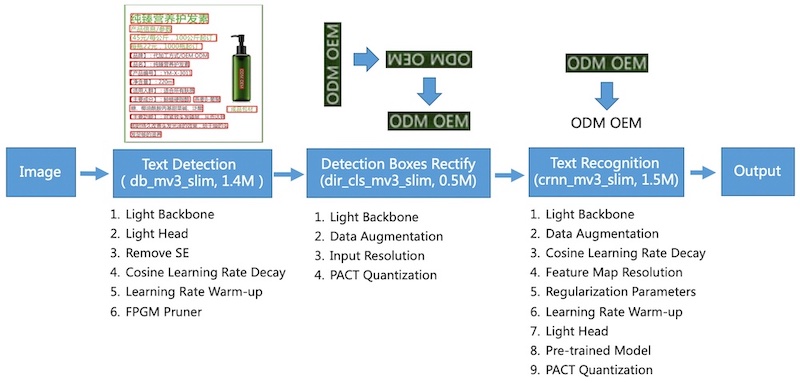
一方のPaddleOCRは中国のBaiduが中心となって開発しているAIフレームワークのPaddlePaddleで開発されたAIOCRモデル。Githubでこちらにソースが公開されている。テキストを検出し、文字の向きを認識し、最後に文字を認識するというフローになっている。文字が回転していても読めたりなど、今時点で一番応用範囲が広そうなモデルである。
試行結果
今回使用したのは以下の2枚の画像 でEasyOCR、PaddleOCRともにGoogle Colabに環境を構築して、読み取り結果を見てみた。


まずはGiftショップ画像でのEasyOCRとPaddleOCRとの結果。文字の後の数字は確度(自信度)を表している。EasyOCRは”LAMINTON!”の読み間違いや、大文字小文字の違い、少し長めの文字列が分割されてたりする。一方でPaddleOCRの方は確度も高く、スペースの違いはあるもののほぼ完璧に読み取れている。ちなみに両方とも”$3″は読み取れていない。
#EasyOCRでの結果
'feed The', 0.5367363750860014
'ALPACAS!', 0.7544091671728653
'Feed Bags Available from Gift', 0.9522704282793588,
'GIFT SHOP OPEN', 0.9308079420466931
'LAMINGTOHI', 0.4652706083076031
'shop', 0.6072659492492676#PaddleOCRでの結果
'FEED THE', 0.9630775451660156
'ALPACAS!', 0.9933735132217407
'Feed Bags Available from Gift Shop', 0.9328293800354004
'GIFTSHOPOPEN', 0.9972817897796631
'LAMINGTON!', 0.9825330972671509
もう一つの看板の方であるが、こちらは日本語が2列の縦書きになっていて難易度は高かったかもしれない。縦書き部分は両方ともに読み取りは出来ていない。EasyOCRは日本語モデルを選択するとアルファベットの読み取り精度が落ちるようで、最後のCREATEも読めなくなってしまっている。PaddleOCRは縦書きは読めないものの、それ以外は影響なく読むことができており、確度も高い。
#EasyOCRでの結果
'止まれ', 0.38396882636889124
'STOP', 0.9984590411186218
'=', 0.0032755751596239002
'雷', 0.0026048600267304517
'9田', 0.005927729409790493
#PaddleOCRでの結果
'止まれ', 0.9996239542961121
'STOP', 0.976591169834137
'商画山', 0.532843828201294
'CREATE', 0.9985430836677551
まとめ
PaddleOCRの方が精度が良く、またかなり小さい文字も正確に読めており、実用性は高いように感じた。これぐらいの精度で読み取れると、十分色々なアプリケーションに実装ができそうだ。